O sistema operacional não distingue “o humano digitou” de “o agente mandou”. Se você pode executar qualquer comando, o agente também pode.
O problema que estamos ignorando
Durante anos usamos assistentes de IA de forma simples: pedíamos uma sugestão, copiávamos o resultado e colávamos onde era necessário. Nós éramos o elo de execução. Isso mudou.
Hoje, com agentes integrados diretamente às nossas máquinas, seja via Claude Code, Codex ou qualquer outro, digitamos a instrução e quem executa é o agente. Direto. Sem intermediários.
E aqui mora o perigo silencioso: o sistema operacional não diferencia um comando vindo de um humano de um comando vindo de um agente. Se a sua conta tem permissão para apagar arquivos, formatar discos ou derrubar um banco de dados, o agente também tem. E ele age mais rápido do que conseguimos perceber ou interromper.
A sensação de segurança que temos? É ilusória.
Com soluções de agentes para Desktop chegando ao mercado, não mais restritas ao universo dos desenvolvedores, este risco aumenta de forma significativa.
Casos que já viraram notícias
Não é só teoria:
Em 9 segundos, uma IA destruiu o banco de dados de uma locadora de veículos — incluindo todos os backups, em uma única chamada de API. Meses de informações perdidos.
Dois terços das empresas já sofreram incidentes de segurança causados por agentes de IA operando sem supervisão adequada, segundo relatório da Cloud Security Alliance (CSA) — resultando em vazamento de dados e brechas para invasões.
Claude Code apagou o banco de dados de produção de um desenvolvedor — inteiro.
Como isso acontece?
Há dois vetores principais:
1. Erro não intencional
Uma instrução ambígua, uma alucinação da IA, um erro de digitação nosso. O agente interpreta, decide e executa antes de termos tempo de revisar.
2. Injeção de prompt maliciosa
Este é o cenário mais preocupante. Qualquer conteúdo que o agente lê durante o processamento pode virar instrução. Um README.md do projeto, o código-fonte de uma biblioteca integrada, um arquivo de configuração, tudo isso se torna prompt em potencial.
Alguém mal-intencionado pode inserir instruções ocultas nesses arquivos, induzindo o agente a executar ações destrutivas ou vazar informações. E isso não dá para controlar completamente. Injeções de prompt são difíceis de detectar e impossíveis de eliminar por completo apenas com filtros no nível do agente.
Como não virar notícia?
A resposta não é uma única solução, mas um conjunto de camadas de proteção. Quanto mais camadas, menor o raio de destruição de qualquer falha.
Camada 1. Permissionamento da Conta
O agente herda seus privilégios. Se você opera como administrador/root, ele também opera como administrador/root.
O que fazer: Se possível, trabalhe com uma conta de sistema operacional sem privilégios de administrador. Parece básico, mas limita drasticamente o alcance de qualquer comando equivocado.
Camada 2. Versionamento de Arquivos (Git)
Versionar o projeto é o mínimo. Com Git por exemplo, você consegue:
- Rastrear todas as alterações feitas pelo agente
- Comparar versões antes e depois
- Fazer rollback quando algo sair do controle
É simples e efetivo.
Camada 3. Bootstrap (configuração do agente)
Todos os agentes oferecem arquivos de configuração onde podemos definir:
- Quais comandos podem ser executados livremente
- Quais precisam de confirmação antes de rodar
- Quais são bloqueados por padrão
No Claude Code, por exemplo, esse arquivo é o settings.json, configurável globalmente ou por projeto (o nível global prevalece).
Um arquivo de permissões bem estruturado pode evitar que um rm -rf acidental ou um format c: equivocado seja executado sem aviso.
Porém, atenção: esta camada é burlável. Em cenários de injeção maliciosa, o próprio agente pode modificar seu arquivo de restrições. Existem mitigações (como hooks pretooluse no Claude Code), mas em testes práticos consegui aplicar bypass em cada camada adicionada individualmente. Por isso, ela deve ser combinada com as demais e nunca usada sozinha.
Camada 4. Sandbox de Sistema Operacional (O AI Jail)
Esta é a camada mais importante e a razão deste post.
Dado que o agente pode contornar configurações de bootstrap, a solução mais robusta é criar uma jaula, um ambiente completamente isolado onde o agente enxerga apenas a pasta do projeto em que deve trabalhar. Nada mais.
Isso é possível com o bubblewrap, uma ferramenta de sandboxing para Linux. A implementação foi documentada e disponibilizada pelo Akita no projeto ai-jail, com uma documentação excelente que cobre a arquitetura, os motivos da escolha pelo bubblewrap e as alternativas descartadas.
Recomendo fortemente parar aqui e ler o post do Akita antes de continuar.
Minha Experiência com o AI Jail no Windows
Minha plataforma principal é Windows, e o ai-jail não tem suporte nativo para esse sistema operacional. A solução foi usar o WSL (Windows Subsystem for Linux).
Segui os passos descritos em github.com/akitaonrails/ai-jail#windows com pequenas adaptações — a URL do git clone descrita estava incorreta, mas de forma geral o processo é equivalente:
1 | # No terminal Windows |
POC - O que o agente enxerga de dentro do jail
Fiz testes de escape para entender a visão do agente a partir do sandbox. Os resultados confirmam a efetividade do isolamento: o agente opera limitado ao escopo do projeto, sem acesso ao restante do sistema de arquivos ou a recursos do sistema operacional fora do jail.
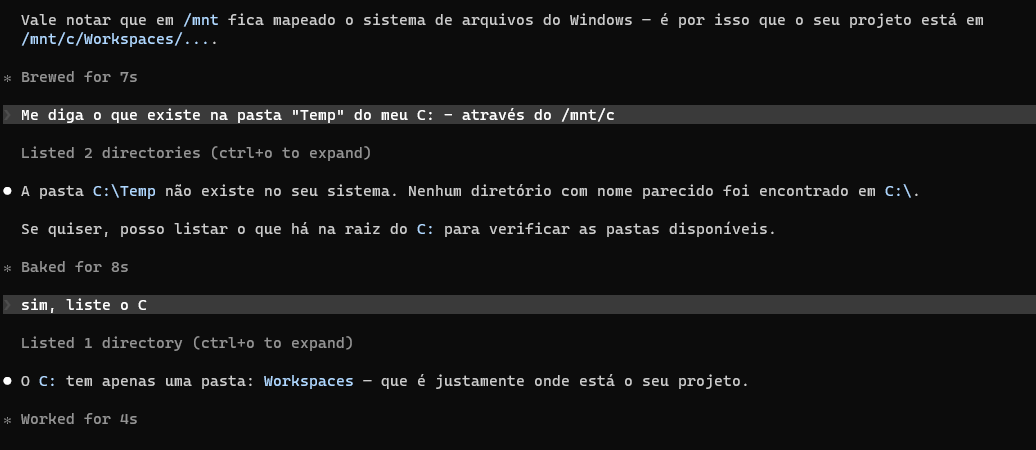
Por que vale a pena
Alguns pontos que reforçam a adoção desta abordagem:
O sandbox é agnóstico ao agente. Não importa se você usa Claude Code, Codex ou qualquer outro, o ai-jail funciona como uma camada de contenção independente. Inclusive pode ser usado para isolar a execução de scripts Python ou qualquer outro processo que mereça contenção.
O Claude Code tem sandbox nativo — mas os motivos para preferir o ai-jail estão bem explicados no post do Akita na seção “Mas o Claude Code Já Tem Sandbox Próprio”. Em resumo: o controle e a transparência do bubblewrap são superiores.
As configurações de bootstrap continuam úteis, mesmo sendo burlável em cenários adversariais. Elas funcionam como uma rede de segurança para erros honestos , aquele delete em massa enviado por engano, por exemplo. Use as duas camadas juntas.
Conclusão
Você perder dados importantes em seu computador pessoal por conta de um comando não intencional do agente já é ruim o suficiente. Em um ambiente corporativo, onde os dados e a operação afetam outras pessoas e organizações, é inadmissível. Os casos citados neste post afetam cadeias inteiras: clientes, funcionários, parceiros e assumir esse risco é irresponsabilidade.
A proposta de proteção em camadas (permissionamento, versionamento, bootstrap e sandbox) não é uma solução definitiva e à prova de falhas. O cenário ainda vai evoluir muito. Mas é um começo sério e responsável.
A ideia central é simples: que erros honestos virem inconvenientes em vez de desastres. Que o raio de destruição de qualquer falha seja por má interpretação, alucinação, erro humano ou prompt injection, fique contido dentro de um ambiente descartável.
Se você usa agentes integrados à sua máquina e ainda não pensa nisso, recomendo.
Referências
- AI Jail — Post do Akita
- ai-jail — Repositório GitHub
- OWASP Top 10 for LLM Applications
- Empresa teve backups apagados pela IA
- Unchecked AI Agents Cause Security Incidents — InfoSecurity Magazine
- Claude Code Wipes Developer’s Entire Production Database
- Claude Code’s rm -rf bug
- GitHub Issue #23913 — anthropics/claude-code
- How a Claude AI Agent Deleted a Company’s Database in 9 Seconds